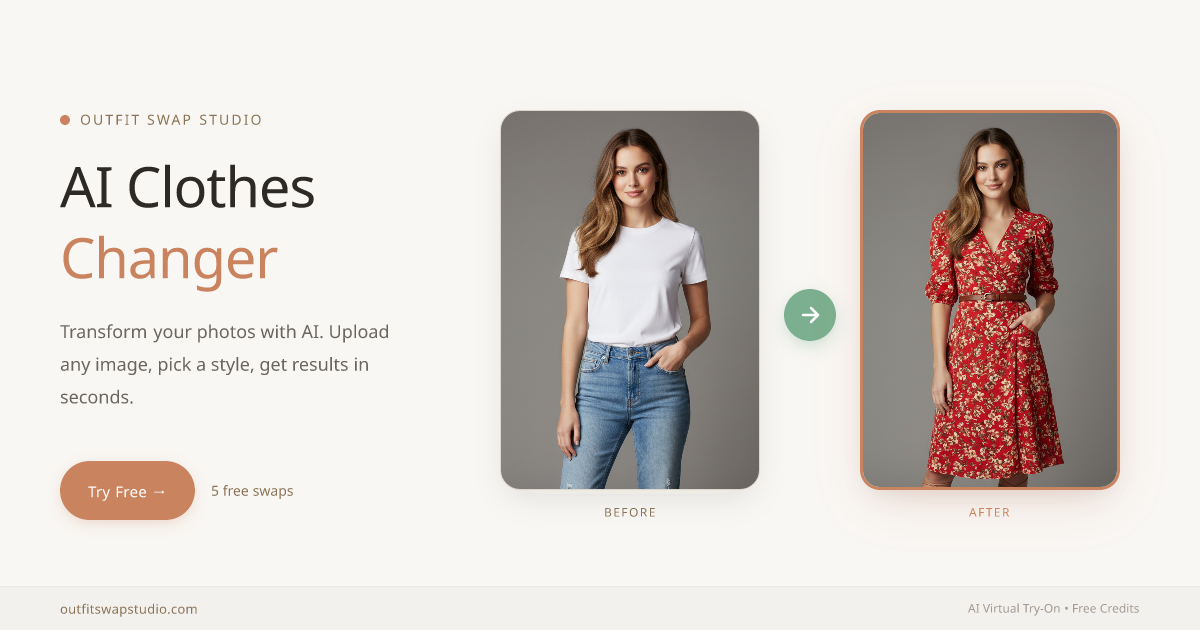
Outfit Swap Studio
AI virtual try-on / outfit swap for user photos. Generates outfit-changed results while aiming to preserve the original face and background for consistency.
ai-fashionfree
1340
AI virtual try-on / outfit swap for user photos. Generates outfit-changed results while aiming to preserve the original face and background for consistency.
A toolkit for training language models to work with PDF documents in the wild.

Umi-OCR is a free, open-source offline OCR app for Windows and Linux. It recognizes text from screenshots, images, PDFs, QR codes, barcodes, and math formulas locally on your device, with Paddle and Rapid OCR builds for accuracy or speed.
An open academic discussion community based on the arXiv platform that allows users to comment line-by-line, ask questions, and interact in real-time.

Chat YouTube is a lightweight AI tool for summarizing YouTube videos and asking questions about their content. It is useful for students, researchers, and busy viewers who need quick notes from public videos, but output quality depends heavily on transcripts and video clarity.

"ChatGPT for YouTube" is a free Chrome Extension that offers instant access to video summaries on YouTube. Quickly grasp video content, save time, and enhance your learning experience.
Seamless is a family of AI models that enable more natural and authentic communication across languages.

MuseGen is an AI music generator for turning prompts, moods, and custom settings into songs with lyrics, melodies, vocals, and mastering-style output. It is useful for creators who want fast song drafts, instrumental ideas, vocal concepts, and music-video experiments.

Generate unlimited unique sound effects for any project with AI. No experience required. No credit card needed.

Generate unlimited high-quality AI sounds with OptimizerAI

Stable Audio is Stability AI’s generative audio platform for creating music, loops, stems, ambience, and sound effects from text prompts. The Stable Audio 3.0 family includes models for artistic experimentation, with open-weight options for research and local creative workflows.
Open source library for audio/music generation by Meta, which mainly includes two models, MusicGen: text-to-music model, AudioGen: text-generated sound model.
Bark is a transformer-based text-to-audio model created by Suno. Bark can generate highly realistic, multilingual speech as well as other audio - including music, background noise and simple sound effects.
ElevenLabs Sound Effects is a text-to-sound-effects generator for creating custom SFX, ambience, loops, and cinematic audio from prompts. It supports prompt-based sound design, duration control, prompt influence, looping effects, multiple variations, downloads, and API workflows for video, games, podcasts, and apps.
Text to music

Create music from simple text prompts by specifying topics, genres, and other descriptors which are then transformed into professional quality tracks.

Create stunning original music for free in seconds using AI. Make your own masterpieces, share with friends, and discover music from artists worldwide.

Split vocal and instrumental tracks quickly and accurately with LALAL.AI. Upload any audio file and receive high-quality extracted tracks in a few seconds.

Separate voice from music out of a song free with powerful AI algorithms
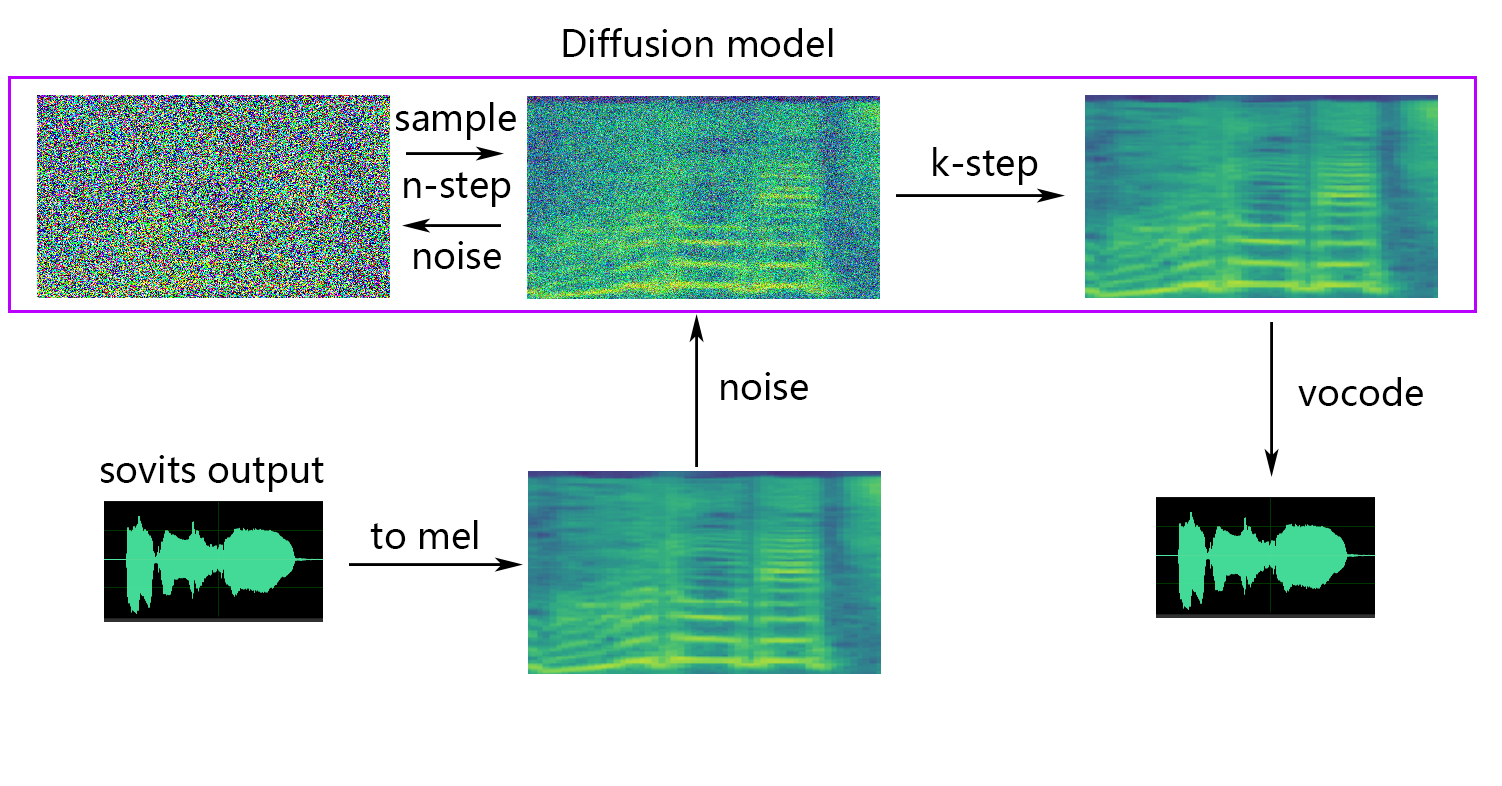
So-VITS-SVC is a free open-source singing voice conversion project built around SoftVC and VITS. It is used to convert singing audio into another trained voice timbre for research and creative experiments, but it requires datasets, model training, GPU knowledge, and careful consent/copyright review.

Shazam is Apple’s music recognition app for identifying songs playing nearby or inside other apps. It is useful for listeners, DJs, creators, and marketers who need fast song IDs, lyrics, videos, concert discovery, and Apple Music or playlist follow-up.
ChatTTS is a text-to-speech model designed specifically for dialogue scenario such as LLM assistant. It supports both English and Chinese languages.

Tetos is an open-source Python and CLI wrapper that provides a unified interface for multiple text-to-speech providers. It is useful for developers who want to compare or switch between Edge TTS, OpenAI, Azure, Google, Volcengine, Baidu, Minimax, Xunfei, Fish Audio, and other engines without rewriting every integration.
EmotiVoice is a free open-source multi-voice, prompt-controlled TTS engine from NetEase Youdao. It supports English and Chinese speech synthesis, more than 2,000 voices, emotional prompt control, and local deployment for researchers, developers, creators, and voice application prototypes.