
Perplexity
AI-driven conversational search engine.
ai-searchfree
1590


turbovec is a vector index built on TurboQuant with Rust and Python bindings, aimed at teams that want dense retrieval with lower memory cost, strong search speed, and local deployment instead of managed vector infrastructure.
87
Views
0
Likes
Jun 2026
Added
github.com
Website
A quick visual look at turbovec before you visit the official site.
Editorial Review
turbovec sits in the retrieval layer rather than the model layer. The pitch is simple: compress vector corpora harder, keep search fast, and avoid the extra training or service overhead that often comes with approximate nearest-neighbor infrastructure.
It is hot now because RAG builders are re-examining infrastructure cost, not just model cost. turbovec pairs a concrete memory story with benchmark claims against FAISS and ships in formats developers can actually use today through Rust and Python.
What attracts attention is that turbovec makes a hard infrastructure claim developers can evaluate: less RAM and competitive speed versus FAISS. The caution is equally technical: benchmark wins do not automatically translate to every dataset shape, filter pattern, or production recall target.
This is infrastructure, not a plug-and-play business app. Teams still need to benchmark their own embedding dimensions, filtering patterns, recall tolerances, and operational tooling. The project also competes in a mature ecosystem where integration effort matters as much as raw speed.
Alternatives include FAISS, HNSW-based libraries, managed vector databases, and other compression-oriented ANN stacks.
Visit the official website to get started
Have an AI tool to share?
Get your product in front of people actively exploring AI tools.
Submit Your ToolAI-driven conversational search engine.

Skip the groundwork with our AI-ready API platform and ultra-specific vertical indexes, delivering advanced search capabilities to power your next product.
Open source AI-driven search engine for private documents
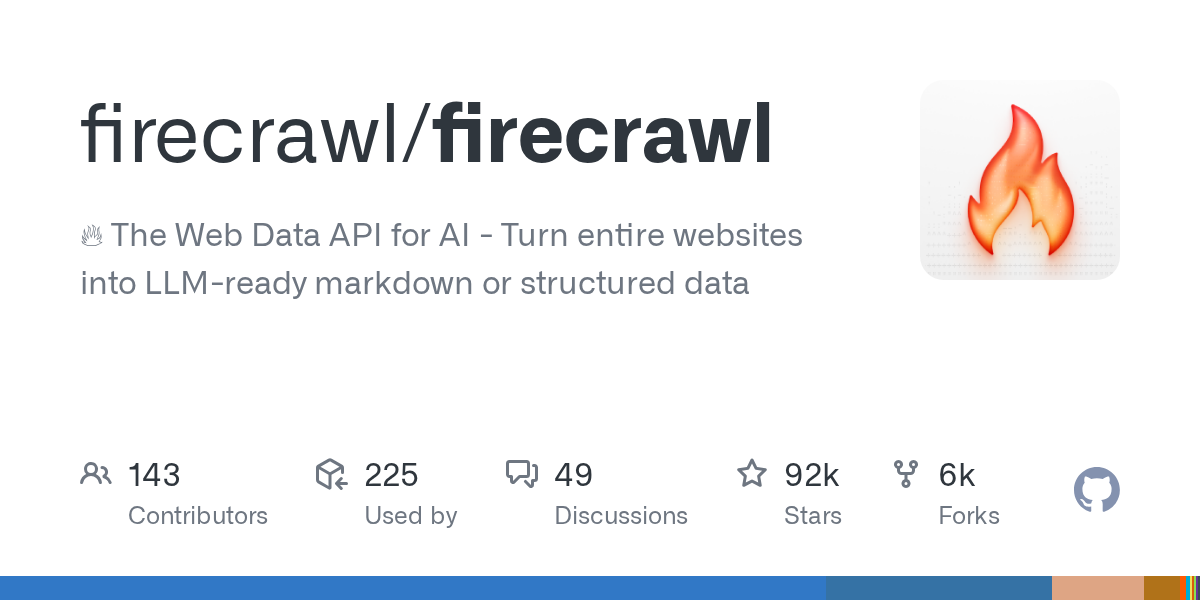
An API built for AI agents that turns entire websites into LLM-ready markdown or structured data.